Background
We've seen the process of converting and ε-NFA to an NFA. This process will be extremely helpful in converting regular expressions into a state machine that's easy to use. However, NFAs may still have multiple transitions for the same input symbol from the same state, which can still make the recognition process difficult. In this section, we'll demonstrate how to convert an NFA into a DFA in order to provide a simpler recognition mechanism.
Example
Example
The following NFA contains multiple transitions for the same input symbol from the same state:
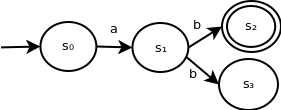
This NFA recognizes the language L = {ab}. When parsing the string ab, after we encounter symbol b in state s1, we can choose to transition to state s2 or s3. Since we are only looking for a single path to an accepting state, we would choose to transition to s2 and accept the string.
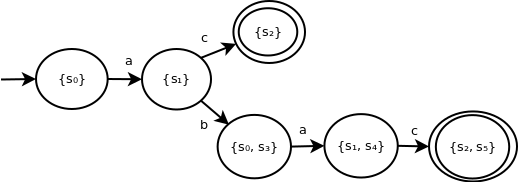
As a result, this NFA is equivalent to the following DFA:

More complex example
Example
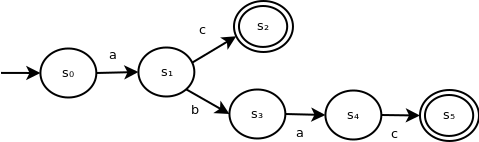
The following is an example of an NFA that is significantly more complex:
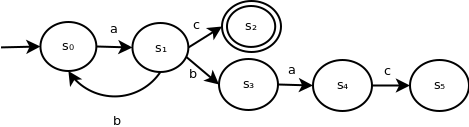
Here, it's less clear how to reduce this to a DFA.
Now, consider the transitions from s1 for input symbol b. The possible set of next states is: {s0, s3}.
Since we only need to find a single path for a certain input string to an accepting state, we would continue the process of considering the set of all possible next states as we iterate through the input string.
For example, if we process input characters a then b, our possible set of states is {s0, s3}. On subsequent input symbol a, the next set of possible states is: {s1, s4}.
Reduction process
To outline the reduction process, for our set of states S, we must consider the power set of S.
Defintion
Given our set of states
S = {s0, s1, ..., sn - 1}
The power set of S is defined as:
P(S) = {{}, {s0}, ..., {sn - 1}, {s0, s1}, {s0, s2}, ..., {sn - 2, sn - 1}, {s0, s1, s2}, ..., {s1, s2, ..., sn - 1}}
Informally, the power set of S is the set containg all possible subsets of S.
Since, as illustated above, we need to consider combinations of possible states, we will construct a new set of states in our DFA which maps to some combination of states from our DFA. Specifically, these combinations map to some element of the power set of S, P(S).
Our DFA's start state corresponds to the element {s0} from P(S), since this is where our parsing process starts.
Next, we must consider the process of working through the NFA to add additional states to our DFA.
We will consider a DFA state which represents some set of states from the original NFA. For each input symbol corresponding to a transition from any of the original DFA states, track all states from the DFA that would be transitioned to for that input symbol. Then, we create a new DFA state corresponding to that set of NFA states (or reuse the DFA state corresponding to that combination if one exists). Then, we can add a transition to it from the previous state.
We set our new DFA state to accepting if at least one of the NFA states it was derived from is accepting.