RIPAL: Responsive and Intuitive Parsing for the Analysis of Language
Pages
Nondeterministic finite automata
Overview
A nondeterministic finite automaton (NFA for short) is another tool that can be used to recognize strings as part of a regular language.
Example of an NFA
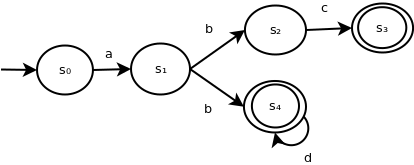
The following is an example of an NFA:
It contains 5 states and 5 state transitions.
State s0 is the initial state, while s3 and s4 are accepting states.
State s1 illustrates a construction that is not allowed in a DFA but is allowed in an NFA: a state with multiple transitions for the same symbol.
This NFA accepts the language represented by the following regular expression:
R = abc ∪ abd*
Anatomy
In general, an NFA consists of:
A set of states, S, typically labelled s0 through sn - 1
One state is the initial state, si - typically s0 by convention
Any number of states can belong to the set of final states, Sf
Sf ⊆ S
A set of transitions, T, between states, consisting of a start state ss ∈ S, an end state sf ∈ S and a transition symbol t ∈ Z
In an NFA, we have a few inherent structural restrictions, as follows:
T = T[si, t] = {sf1, sf2, ..., sfn}, a set of states
This differs from DFAs which only allow a single state per combination of ss and t
t ∈ Z, a single symbol in our alphabet
The NFA parsing algorithm
To determine whether s = {σ1σ2...σn} belongs to the language recognized by NFA with states S, transitions T[si, t], initial state si:
Set Scurrent = {si}
For i = 1 to n
symbol = σi
Snext = {}
For each scurrent in Scurrent
snext = T[scurrent, symbol]
If snext exists
Add snext to Snext
If Snext is empty
Reject
Scurrent = Snext
End for
If Scurrent contains an accepting state
Accept
Otherwise
Reject
Informally, we are running our NFA algorithm but instead of tracking the next definitive state, we track all possible states that could be reached through the next transition.
We reject the language if we end with a set of states at the end of our input that does not contain an accepting state or run out of possible transitions. Note that it's sufficient to find just one successful path through the NFA for it to accept an input string.
Parsing examples
Example
For s = abc
States
Input symbol
Action
{s0}
a
Transition to {s1}
{s1}
b
Transition to {s2, s4} (since s1 has two transition for symbol b)
{s2, s4}
c
Transition to {s3} (since s2 has a transition to s3 for symbol c, while s4 has no valid transition for c)
{s3}
$ (end of string)
Accept (since Scurrent contains s3 which is an accepting state)
Example
For s = ab
States
Input symbol
Action
{s0}
a
Transition to {s1}
{s1}
b
Transition to {s2, s4} (since s1 has two transition for symbol b)
{s2, s4}
$ (end of string)
Accept (since Scurrent contain s4 which is an accepting state)
Example
For s = abd
States
Input symbol
Action
{s0}
a
Transition to {s1}
{s1}
b
Transition to {s2, s4} (since s1 has two transition for symbol b)
{s2, s4}
d
Reject (since no transition exists from s2 or s4 for symbol d)
Example
For s = a
States
Input symbol
Action
{s0}
a
Transition to {s1}
{s1}
$ (end of string)
Reject (since Scurrent does not contain an accepting state)
Reflection
An NFA is a less structurally restrictive iteration of a DFA.
Despite this, we will later illustrate that the set of languages that can be recognized by these tools are equivalent.